Ever tried running a massive AI on your Mac only to see a “Failed to load model” error? It is frustrating when you know your hardware should be able to handle it. Let’s dive into how we can “borrow” more memory for your GPU to make those Large Language Models run smoothly.
Running Large Language Models (LLMs) locally is one of the most exciting things you can do with a modern Mac. However, if you are using a base model MacBook Air or Mac Mini with only 16GB of Unified Memory, you might hit a wall. When you use a tool like LM Studio to load a popular model—for example, the GPT-OSS 20B—you might notice it requires around 12.34GB of memory. On paper, 16GB should be enough, right? Unfortunately, macOS does not work that way.
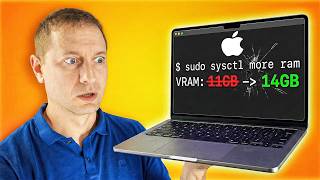
In the world of Apple Silicon (M1, M2, M3, and M4 chips), we use what is called Unified Memory Architecture. This means the CPU and the GPU share the exact same pool of RAM. However, by default, macOS is very protective. It usually reserves about 25% to 33% of your RAM for the system itself. It needs this space for the “Kernel,” “WindowServer” (which draws your screen), and various background tasks. This is why LM Studio might tell you that your VRAM capacity is only around 11.84GB even though you have 16GB installed. If your AI model needs 12GB, the system will simply refuse to load it, leading to that annoying “failed to load” message.
To fix this, we have to talk to the Mac’s “brain” using the Terminal. There is a specific system control command that manages how much memory the GPU is allowed to “wire” or lock for itself. The technical term for this is iogpu.wired_limit_mb. By default, this value is often set to ‘0’, which tells the Mac to use its standard, safe percentage. But as tech explorers, we can override this!
First, you need to check your current limit. You can open your Terminal and type a command to see the status. If it says 0, you are on the default settings. To change it, you use a sudo command, which stands for “SuperUser Do.” It tells the computer, “I know what I’m doing, let me change the system rules.” For example, if you want to set the limit to 8GB, you would use the number 8192. Why such a weird number? In computing, we work in powers of two. 1024 megabytes equals 1 gigabyte, so 1024 times 8 is 8192.
If you are feeling brave, you can push the limit even higher. In our testing, setting the limit to 14336 (which is 14GB) on a 16GB machine allows almost the entire memory pool to be used by the GPU. When you do this and restart LM Studio, you will see the VRAM capacity jump up significantly. Suddenly, that 12GB model that used to crash now loads perfectly! You can watch your “Memory Pressure” in the Activity Monitor. It will likely turn yellow, which means the Mac is working very hard and using “Swap” memory (using your SSD as temporary RAM), but the AI will actually function.
When the model is running, you can track its performance in “tokens per second.” This is basically how fast the AI can “think” and write words. Even on a base MacBook Air, you can get impressive speeds once the memory bottleneck is removed. However, there is a catch. If you give all the RAM to the AI, your other apps might become very slow. Your web browser might lag, or your background music might stutter. This is because the system no longer has enough “breathing room” for its own basic operations.
For a 16GB machine, a balanced setting like 14GB for the GPU is usually the limit of what is usable. If you have a more powerful setup, like a cluster of Mac Studios with 512GB of RAM each, this trick becomes even more powerful, allowing you to run gargantuan models that would normally require tens of thousands of dollars in specialized server hardware.
This method is a game-changer for students and hobbyists who want to experiment with the latest AI technology without buying the most expensive Pro or Max chips. It proves that with a little bit of technical knowledge, you can make your hardware do things the manufacturer never intended. Just remember to always keep an eye on your system heat and memory pressure!
By understanding how Unified Memory allocation works, you can effectively “download more RAM” (digitally speaking) and turn your everyday laptop into a powerful AI workstation. If you ever want to go back to normal, just set the limit back to 0 or restart your Mac, and the system will return to its safe, default behavior. Happy prompting!